
Python と matplotlib を使って手軽に統計データを可視化してみよう!
以前、下記の記事で R 言語を使って統計データを可視化する方法をご紹介しました。
「 R言語で統計データを可視化しよう!R言語グラフ入門 」
R 言語でも手軽にデータの可視化をすることができるのですが、
実は Python でも簡単にデータの可視化をすることができます。
今回は matplotlib というグラフ描画ライブラリを使用して、
Python でデータを可視化する方法をご紹介します!
事前準備
まず、 matplotlib とは、 Python でグラフを描画する時によく使用されるライブラリです。
どのようなグラフを描画することが出来るのかはギャラリーから見ることができます。
グラフ描画には scikit-learn に付属しているデータセットを使用します。
今回使用する環境としては、
- Python 2.7
- matplotlib 2.0.2
- numpy 1.13.0
- scipy 0.19.1
- scikit-learn 0.18.2
を使用して進めていきます。
最初に必要となるモジュールをインストールしましょう。
$ pip install numpy scipy scikit-learn matplotlib作成するファイルの先頭で以下のようにモジュールを読み込みます。
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
これで準備完了です、それではグラフの描画をしていきましょう!
グラフを描画してみよう
線グラフ
Sin 波と Cos 波を掛け合わせた線グラフを作成してみましょう。
Numpy を使えば、対象区間の数学関数波形を簡単に作成することが出来ます。
グラフの掛け合わせは plt.plot 関数をグラフの数だけ実行するだけです。
最後に plot.show() 関数を実行することでグラフ描画が行われます。
def line():
x = np.arange(-np.pi, np.pi, 0.1)
sin_y = np.sin(x)
cos_y = np.cos(x)
plt.plot(x, sin_y)
plt.plot(x, cos_y)
plt.show()

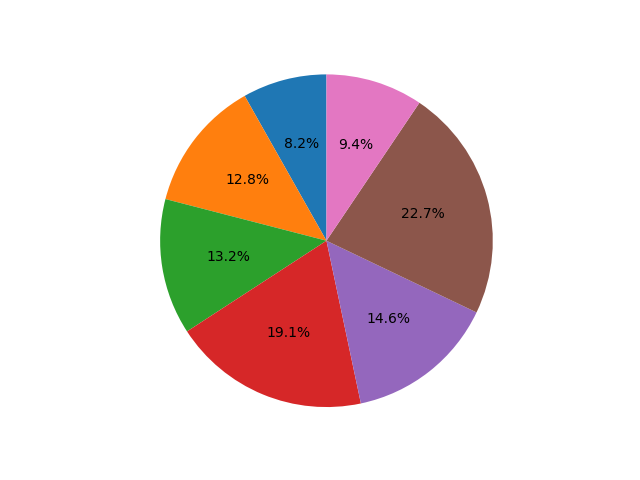
円グラフ
円グラフは plt.pie 関数で作成することができます。
20から70までのランダムな数値を7個作成し、
それを円グラフに落とし込んでいます。
環境によっては plt.pie だけだと潰れた楕円形となってしまうため、
plt.axis('equal') を指定することで問題なく表示されるようになります。
def pie():
sizes = np.random.rand(7) * 70 + 20
plt.pie(sizes, autopct='%1.1f%%', startangle=90)
plt.axis('equal')
plt.show()
ヒストグラム
ヒストグラムは plt.hist 関数で描画することができます。
平均が20で標準偏差が10の正規分布と、
平均が40で標準偏差が10の正規分布を重ねて描画しました。
plt.hist 関数の引数に alpha を指定することで透明度を変えたり、
plt.legend 関数で凡例を表示することができます。
def hist():
x = np.random.normal(20, 10, 100)
y = np.random.normal(40, 10, 100)
plt.hist(x, label = "x", bins=20, alpha=0.5)
plt.hist(y, label = "y", bins=20, alpha=0.5)
plt.legend()
plt.show()

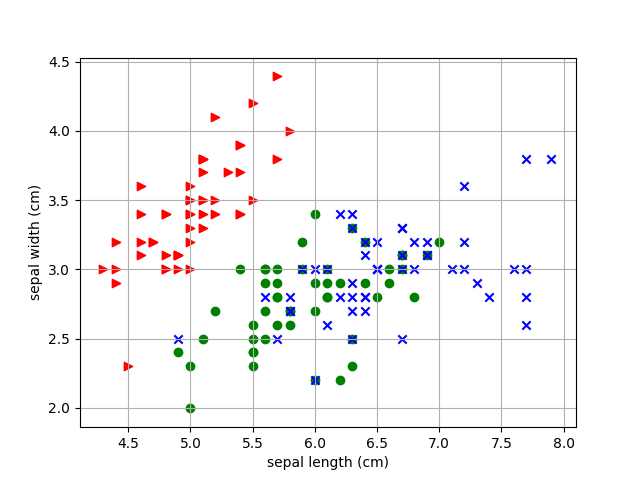
散布図
最後に scikit-lean に付属している iris のデータセットを使用して
散布図を描画してみましょう。
菖蒲の萼片の長さと幅を品種ごとに散布しています。
散布図は plt.scatter 関数で引数に x 軸、 y 軸のデータと、
マーカーの種類、色を指定します。
def scatter():
iris = datasets.load_iris()
features = iris.data
feature_names = iris.feature_names
targets = iris.target
for t, marker, color in zip(range(3), '>ox', 'rgb'):
plt.scatter(
features[targets == t, 0],
features[targets == t, 1],
marker=marker,
c=color
)
plt.xlabel(feature_names[0])
plt.ylabel(feature_names[1])
plt.autoscale()
plt.grid()
plt.show()
まとめ
Python は R 言語ほど手軽ではありませんが、
R 言語でプロトタイプを作成して Python でプロダクトに組み込むという
開発サイクルを回すことができると思います。
今後も R 言語と Python 両方の観点からみたデータ処理を記事にしていきますので、
お楽しみにお待ち下さい!














記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。