















機械学習でプロ野球の勝敗予想をやってみた!
当社では、「SPAIA」という、従来のスポーツニュースメディアとは違った、スポーツデータを AI によって解析し、新しいスポーツの見方や楽しみ方が実現できるサービスを提供しており、弊社独自で編集部が取材・編集したオリジナルコンテンツも掲載しています。
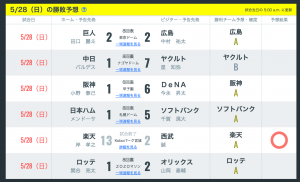
近日、プロ野球の 「勝敗予想」 を行うサービスをリリースしました。
そこで、今回は勝敗予想の簡単な AI の仕組みと、今後の展望をご紹介したいと思います。
-
■ どうやって予想しているの?
勝敗予想を行う手法には、WAR(Wins Above Replacement)などの指標を利用する統計的手法など、色々な手法がありますが、当社では machine learning(機械学習)を用いた手法を採用しています。
まず、当社との提携企業様から定期的に提供して頂いているデータを基にコンバートを行い、対象となる対戦チーム毎の組み合わせをベクトル化します。そして、そのベクトルデータを Classifier(分類器)を用いて、勝敗の確度を A 〜 C の3段階の基準で算出しています。
また、分類器としては、現在は Random Forest(ランダムフォレスト)を利用しています。

このように、算出された、基準値を基に次回の対戦チーム毎の勝敗予想を算出しています。
■ なぜ、Random Forest(ランダムフォレスト)?
現在、machine learning(機械学習)の Classifier(分類器)と言えば、Deep Learning(深層学習)が非常に注目されていますが、現在はあえて Random Forest(ランダムフォレスト)を利用しています。
Random Forest(ランダムフォレスト)を利用しているのは、大きな理由として、まだリリースして間もなく、解析に対しての有用な特徴変数を見出せておらず、それを見出すためです。
Random Forest(ランダムフォレスト)は以下のメリットとデメリットがあります。
■ ランダムフォレストのメリットとデメリット
・メリット
特徴量のスケーリングが必要ない(SVM などの分類手法では必要になる)
考慮するパラメータが少ない
並列化が容易
どの特徴量が重要かを知ることができる
・デメリット
複雑なデータでは SVM などの分類手法に比べて汎化性能が下がる
このように、現在どの特徴変数が重要を模索している状況なので、あえて Random Forest(ランダムフォレスト)を利用しています。
今後、重要な特徴変数が見出せれば、より分類能力の高い Classifier(分類器)に変更して行く予定です。
■ 最後に
今回は、勝敗予想の簡単なAIの仕組みと、今後の展望をご紹介しました。
弊社には、野球に詳しい人材が多数いますので、毎日 「人間 vs AI」 といった予想の対戦を行いつつ、そこから得られたノウハウを取り込んで行き、より精度の高い勝敗予想の施策を行っています。
是非、勝敗予想精度が向上するのをご期待頂き、勝敗予想をお楽しみ頂ければと思います。















記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。