















教師なし機械学習、クラスタリングについて考えてみよう!
近年、AI (Artificial Intelligence) が様々な分野で、活用されています。その中で重要な技術として、機械学習 (Machine Learning) が挙げられます。
一般的に機械学習 (Machine Learning) には、大きく分けて「教師あり学習」と「教師なし学習」との2種類があります。
そこで、今回は「教師なし学習」である「クラスタリング」をご紹介したいと思います。
-
■ クラスタリングとは?
「クラスタリング」は、データの中での似ている性質の集まりを見出す手法と言え、似たもの集合を作成するというイメージです。
例えば、りんごとレモンとパクチーと青ネギなどの食品のデータとして入手した場合、そのデータをクラスタリングすると、食品の色が特徴として設定されていた場合、パクチーと青ネギが似たもの集合としてでてくるでしょう。緑色の特徴によって似たものとして認識されるためです。
クラスタ (Cluster) といえば、「群れ、集団、一団」という意味似なります。そのような集団をデータから見出します。また、クラス分類とは違い、分け方を事前に教師データを与えるのではなく、データからその集団を見出すということで、事前に教師データは必要ありませんので「クラスタリング」は「教師なし学習」となります。
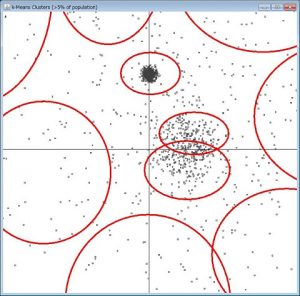
■ どのようなアルゴリズムがあるの ?
クラスタリングといっても、その手法には様々な手法が考案されています。
以下に、代表的な手法の特徴をご紹介したいと思います。
凝集型
➤ボトムアップに近いものからくっつけていく(樹形図ができる)
➤実装が簡単・クラス数を最初に定義しなくてよい
➤クラスタ間の距離がわかりやすい
➤距離計算をどう定義するかが難しい
(単連結(近いところ), 完全連結(遠いところ), 重心)
・単連結 → 長い列みたいなクラスタができる
・完全連結 → 鎖にはならない
k-means法
➤最初にK個のクラスタに分けると決める
➤K個の代表ベクトルを無作為に決める
➤それぞれについて距離が一番近い代表ベクトルのところに所属させる
➤各クラスに含まれる点の平均を取り、それを新しい代表ベクトルにする → 繰り返し
・利点: クラス数が決まっている場合綺麗に取れる
・問題: 初期値依存が大きい, クラス数を決めないといけない, 初期値に凝集型で決めたものを使うとか
混合正規分布によるクラスタリング
➤k-means法をソフトクラスタリングにしたもの
➤全てのクラスタは正規分布に基づいた値を生成すると仮定して、各事例の P(x|C) を決める
➤P(C|x) を、各 x の生起確率と、クラスタの事前分布に基づいて計算する
(クラスタの事前分布は適当に与えるか、テストデータで与えるか)
➤全部の P(C|x) を計算し終えたら、代表ベクトルを再計算する
➤再計算できたら、また P(C|x) を考える
EMアルゴリズム
➤対数尤度最大化によって平均ベクトルの再計算を行いたい
→ が、各事例のCは未知で、P(c|x;θ’) が与えられる
➤対数尤度 ΣlogP(c,x;θ) の代わりに、ΣΣP(c|x;θ’)logP(c,x;θ) を
最大化する θ を探すのが EMアルゴリズムになる
➤EMアルゴリズムは必ずしも事前分布を仮定しなくともよい
➤Q関数は単調増加になる
➤さっきの混合正規分布で適当に与えていた P(C) は、
各事例があるクラスタに属する確率の和を正規化して与えることができる
■ 最後に
今回は「教師なし学習」である「クラスタリング」をご紹介しました。
このように、事前に教師データが必要なくデータの特徴によって、グルーピングできる「クラスタリング」はレコメンデーションなどの手法にも取り入れられたり、マーケティングでは、ユーザーをさまざまな属性(性別、年齢など)や嗜好性、消費傾向を基準にしたいくつかのグループに分類し、ダイレクトメールの配布などにも活用されています。しかしながら、データ量が多くなれば、このような処理は膨大なリソースが掛かってしまします。
次回は、ビックデータに対しても「クラスタリング」を容易に行える、分散処理技術である Hadoop と、Hadoop 上で動作するデータマイニングのライブラリである Mahout を利用した「クラスタリング」をご紹介したいと思います。














記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。