















様々な文章をカテゴライズするIBM Watson Natural Language Classifierを使ってみた
言語処理の分野でも人工知能の活躍は増えてきています。
その中でIBM WatsonのNatural Language Classifierを使ってみました。
NLC (Natural Language Classifier)とは
Natural Language とは自然言語のことであり、人工知能の1分野の自然言語処理のことです。
自然言語処理という言葉は最近ではよく聞くようになってきました。
ではClassifierとはなんなのでしょう?
日本語に翻訳すると分類器となります。
この場合分類器とは統計の分野の単純ベイズ分類器にあたります。
ベイズの定理(条件付き確率)を分類問題(どちらに分類されるかという問題)に適用したものになります。
簡単にいうと文章(自然言語)の意味を解釈して分類するのではなく、文章に登場する単語から文章の分類を決めてしまおうというシステムです。
日本語は英語のようにスペースで単語を区切らないですし固有名詞の1文字目が大文字にもなりません。
その為日本語の形態素解析(単語に切り分けること)は難しいのですが、このWatson NLCは日本語にも対応している数少ないClassifierです。
使った結果
続いて使い方について書いていきたいのですが、先に結果を見た方がイメージしやすいと思いますので実際に分類してみましょう。
Watson NLCはREST APIを用いて学習データを読み込ませ学習することで、その後新たな文章を送った時その文章がどのジャンルに分類されるかが返ってきます。
今回はSiTestブログの最新30記事の序文とその代表カテゴリを学習データとして分類器を作ってみました。
その分類器にこの記事の序文を分類器にかけた所
“classes”: [
{
“class_name”: “AI(人工知能)”,
“confidence”: 0.8296899286053329
},
{
“class_name”: “技術情報”,
“confidence”: 0.12265332176385296
}
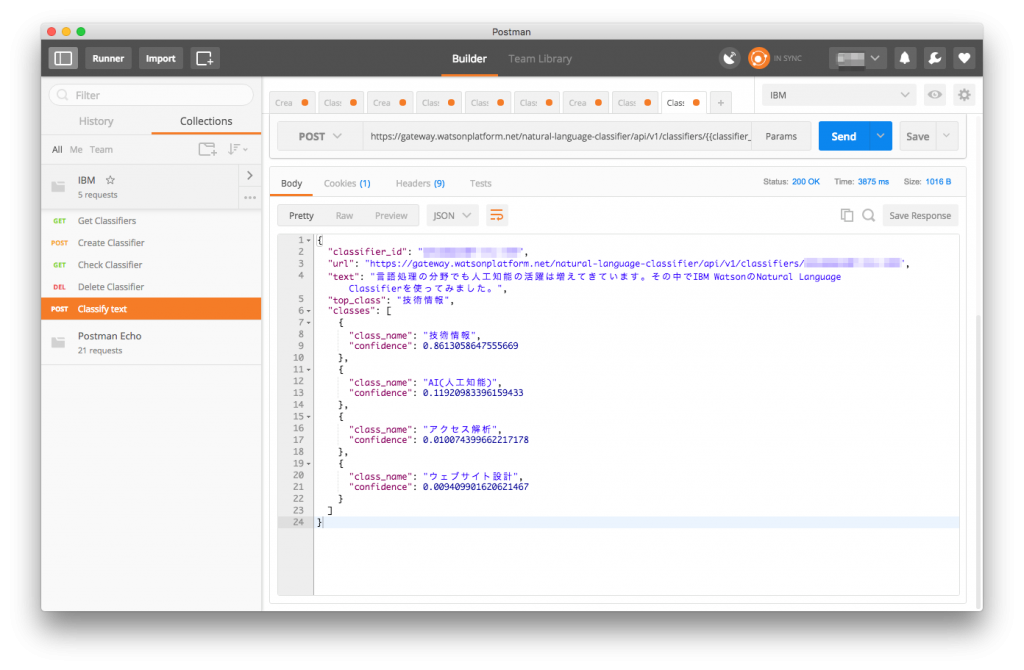
82%でAI(人工知能)の記事だと分類されました。
技術情報の確率も12%と大体正しいです。
それぞれのAPIの使い方
それでは実際に各APIを使ってみましょう。
準備するものとしてBluemixのアカウントとREST APIを使用しますのでAPIを送受信できるアプリ、なければ最悪面倒ですが、ブラウザのコンソールからAjaxを飛ばせばいいと思います。
今回はBasic認証をコンソールから通すのが面倒ですのでPostmanを使用しました。
REST APIは大きく5つあります。どれもBasic認証がかかっていますので、Bluemix管理画面よりパスワードを入手しておきましょう。
・分類器を取得
https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers
上記をGETメソッドでアクセス
登録している分類器を取得します。
classifier_idがこの後使用する分類器のIDになります。
・分類器を作る
https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers
上記にPOSTメソッドでアクセス
training_metadataプロパティに言語と分類器の名前を付け、
training_dataプロパティに学習させたいデータをcsvの形式で送信します。
学習には少し時間が掛かるためしばらくしてから(今回は5分ほど)分類器をチェックするAPIで現在のステータスを確認します。
・分類器をチェックする
https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{{classifier_id}}
にGETメソッドでアクセス
※classifier_idには先程の分類器を取得で得られたIDを入れます。
・分類する
https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{{classifier_id}}/classify
にPOSTメソッドでアクセス
※classifier_idには先程の分類器を取得で得られたIDを入れます。
textプロパティに分類したい文章を入れ送信すると分類結果が得られます。
・分類器を削除する
https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{{classifier_id}}
にDELETEメソッドでアクセス
※classifier_idには先程の分類器を取得で得られたIDを入れます。
分類器を削除します。
新しい学習データで分類器を作り古い分類器が必要ないとき等に実行します。
まとめ
いかがでしたでしょうか?
今回はREST APIで非常に簡単に使え日本語に対応した分類器としてWatson NLCを使ってみました。
今回は学習データが少なかったこともあり完璧というわけにはいきませんでしたが、学習データが増えるれば当然精度も上がっていきます。
メールや問い合わせを分類する手段として優秀ですし分類器を作る手間はほとんど感じないので細目に作り直すこともできます。
人工知能による自動化はこれからもドンドン進んでいくことでしょう。
ちなみにBluemixアカウントは1ヶ月無料で使えます。
無料期間はAPIにリクエストを送る回数も決まっていますが1,000回まで無料だそうです。















記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。