















Python と HBase API を使って Cloud BigTable を試してみよう!
機械学習の広がりによって数テラバイト 〜 数ペタバイトのビッグデータを活用する時代になり、スケーラビリティとパフォーマンスが高いデータベースが求められるようになってきました。
パブリッククラウドサービスを提供している各社とも、
ビッグデータを解析するためのサービスを提供しています。
今回は Google が開発・提供している Cloud BigTable を Python を使って、
チュートリアルを進めながら基本的な動作をご紹介していきます。
Cloud BigTableとは
Cloud BigTable とは Google 社がクラウドサービスとして提供している、
大規模データ向けの分散型列指向型 NoSQL です。
BigTable 自体は Google が 2000年代に開発し、 Google 社内での運用を行っていました。
Googke 検索やアナリティクスなども BigTable を使用しているとされています。
BigTable をモデルとして開発されたデータベースシステムとして
Apache HBase があります。
Cloud BigTable では、 HBase 互換の API も提供しています。
事前準備をしよう
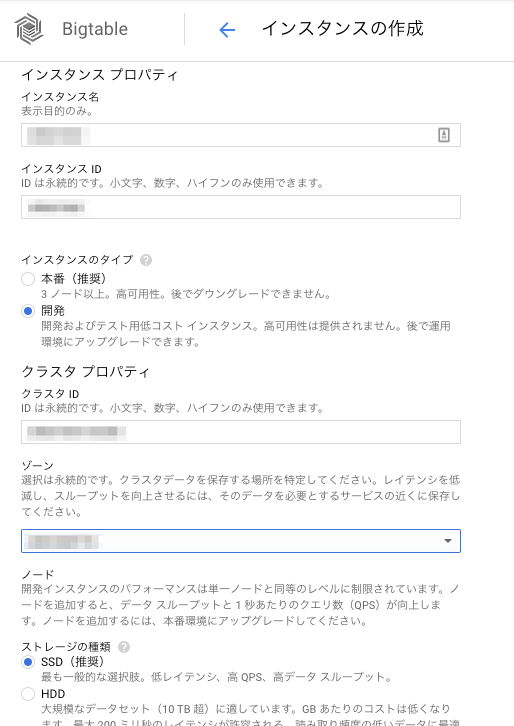
Google Cloud Platform (以下 GCP )のコンソールから BigTable を選択し、インスタンスを作成しましょう。
インスタンス名、インスタンス ID 、ゾーンを決めましょう。
今回はチュートリアルだけを行いますので、
インスタンスタイプは「開発」を選択しましょう。
ストレージの種類は、本番運用を考慮するのであれば、
可能な限り SSD を選択したほうが良いと思います。
問題がなければ、「作成」ボタンを押してインスタンスを作成します。
BigTabe への接続に Cloud SDK が必要となりますので、
あらかじめインストールしておきましょう。
Python で動かしてみよう!
それでは、 Python でチュートリアルを使って基本的な動作をお伝えしていきます。
なお、使用する Python のバージョンは2.7となります。
まずは必要なライブラリを pip コマンドを使用してインストールしましょう。
# requirements.txt
google-cloud-happybase==0.24.0
google-cloud-bigtable==0.24.0
google-cloud-core==0.24.1
次に、先ほど作成した Cloud BigTable のインスタンスへ接続しましょう。
BigTable への接続方法は2種類あります。
1. Cloud SDKを使用する
こちらは、 gcloud コマンドの認証を経由して接続する方法です。
あらかじめ、 gcloud auth application-default login で
アプリケーションから認証できるようにしましょう。
2. サービスアカウントを使用する
Cloud SDK がインストールしづらい環境で BigTable を使用する方法として、
サービスアカウントを使って接続する方法があります。
まずは、 API Manager から下記2つの API を有効化します。
- Cloud Bigtable Admin API
- Google Cloud Bigtable Table Admin API
次に、GCP コンソールの IAM から「サービスアカウント」を選択し、
BigTable Administrator のロールを適用して作成しましょう。
秘密鍵は JSON 方式で作成して任意の場所に設置しましょう。
最後に、下記の環境変数でファイルの場所を指定すれば、
問題なく接続することが出来ます。
export GOOGLE_APPLICATION_CREDENTIALS=/path/to/PrivateKey.jsonそれでは、 Python からインスタンスに接続してみます。
from google.cloud import bigtable
from google.cloud import happybase
def main():
project_id = "gcp_project_id"
instance_id = "bigtable_instance_id"
client = bigtable.Client(project=project_id, admin=True)
instance = client.instance(instance_id)
connection = happybase.Connection(instance=instance)次に、テーブルを作成してデータを入れていきましょう。
# create table
table_name = "apps"
column_family_name = "data"
try:
connection.create_table(table_name, {
column_family_name: dict()
})
except Exception as e:
print(e.message)
# create rows
table = connection.table(table_name)
names = ["John", "Jane", "Richard", "Alan"]
for name in names:
table.put(name, {"data:name": name, "data:age": random.randint(20, 40)})最後に入れたデータを色々な方法で取得してみます。
# get data
print(table.row(names[0]))
for row in table.rows(names[2:]):
print(row)
for row in table.scan(row_prefix="J"):
print(row)table.row メソッドは指定した RowKey を1行取得します。
table.rows メソッドでは RowKey の配列をパラメータとし、一致した行を取得します。
最後の table.scan メソッドが少し変わっており、
データではなくイテレータが返却されるためループを使って実データを取り出す必要があります。
メソッドのパラメータ指定で取得するカラムを制限したり、
指定範囲をスキャンするということもできます。
BigTable はインデックスが RowKey にしか効かないため、
RowKey の設計を慎重に行う必要があります。
また、本番運用では3台以上のクラスタ構成での運用となりますので、
設計次第では本来のパフォーマンスが出せない場合もありますので注意する必要があります。
今回のコードは glad-cube/python-bigtable-sample で公開していますので、全体を通してみたい方はぜひご覧ください。
まとめ
今回は Cloud BigTable での基本的な使い方をご紹介しました。
BigTable は扱いが難しいサービスではありますが、
ビッグデータを高パフォーマンスであるか得ることはとても魅力的です。
今後も Cloud BigTable を使用したアーキテクチャや、
パフォーマンスを出しやすいデータ構造などをご紹介していく予定ですので、
楽しみにお待ち下さい!














記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。