















検索機能に用いられている、特徴語とそのさまざまな抽出方法
普段何気なく使っている検索機能ですが、その中では特徴語の抽出が行われています。その特徴語の抽出方法をいくつか挙げてみます。
特徴語とは
特徴語とは、検索のため記事を特徴づける目的で記事から抽出するのですが、記事がどんなジャンルについて書かれているのかを特定するという目的と、もれなく検索でヒットさせるという目的の2つがあり、その2つの目的はトレードオフの関係にあります。
そのジャンルでしか使われない語句を特徴語として抽出すれば類似の記事を見つけることができますし、一般的な語句を特徴語として抽出すればより多くの結果を見つけることができます。
検索という機能ではこの2つのバランスが大事だと言われており、その抽出には様々な手法が用いられています。
TF-IDF
まず特徴語の抽出で良く用いられる手法としてTF-IDFが挙げられます。
TFとは Term Frequency の略で単語の出現頻度、
IDFとは Inverse Document Frequency の略で逆文書頻度と翻訳されます。
TFは言葉から内容が想像できますが、IDF(逆文書頻度)はいまいちイメージがつかめませんね。
まず前提としてよく出てくる語句は重要な語句という仮説をもとに語句を抽出します。
ただし一般的な語句ほどよく使われるので、それらが重要な語句となってしまいます。
また、重要な語句と言えど記事が長くなるにつれ出現頻度が下がってしまい、逆に一般的な語句ほど頻度が上がってしまいます。
これでは記事の特徴がつかめません。
この問題を解決するのがIDF(逆文書頻度)です。
IDF(逆文書頻度)は特徴語が全記事においてどれくらいの記事で出現するかを表す尺度です。
全記事数のうちからある語句が出現する記事数で割った値の対数に1を加えた値になります。
このIDFはある語句が出現する記事が少ないと大きくなり、どの記事にも出現する場合小さくなります。
このIDFにTFを掛けたものがその語句の重みと考えられます。
この重みによって特徴語を抽出します。
SVM
SVMはSupport Vector Machineの略です。
まず特徴語は話題の中心になりやすく見出しにも登場しやすいという性質を仮定します。
話題の中心になりやすいということは主語や目的語として使われ、前後に助詞が出現する頻度が高いです。
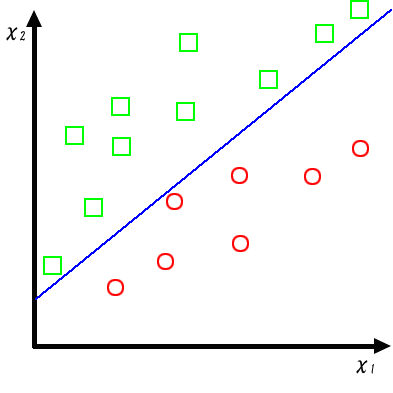
こういった性質を持っている語句を特徴語として分類するためそれらの性質を特徴ベクトルとして考えます。
性質を数値化して座標軸で考え(上記の場合平面)その集合を分類します。
その特徴ベクトルを高次元で分類するのに適した識別器がSVMです。
KeyGraph による手法
これまでの手法はあらかじめデータを用意する必要がありSVMによる分類は計算のコストも高かったのですが、KeyGraphによる特徴語の抽出は事前データは不要であり計算コストも語数にほぼ比例していきます。
ではKeyGraphとはどんな手法なのでしょうか。
記事内で出現頻度の高い語句は記事全体の基本となる土台となっていることが多いという仮定と
その土台に支えられているのが最も伝えたい内容である、つまり特徴語となるという考えに基づく手法です。
まず記事内で出現頻度の高い語句を抽出しその語句が登場する文に同時に登場しやすい(=共起関係が強いといいます。)語句を抽出します。
ただし、意味がなく出現頻度の高い語句はあらかじめ除外しておく必要があります。この除外する語句を不要語といいます。
続いて出現頻度の高い語句と共起関係が強い語句を線で結びます。
切り離すことでその単語へ別の線を辿っていけなくなるような線を切り離します。
これによって閉じたグラフを土台とし、この土台と共起関係の強い語句を抽出します。
ある語句が各土台を含む文に含まれる数の合計をもとめその数値の高い語句がその記事の特徴語となります。
この手法ですと出現頻度の低い語句も特徴語として抽出することができます。
また最初に事前データが不要と書いた通り、一つの記事の中で計算を完結させることができます。
そのため記事が増えても計算量は記事が増えた分だけ増えるといった処理内容となります。
まとめ
今回紹介したような手法を用いて特徴語を抽出し検索した語句がその特徴語とマッチする記事を検索結果として挙げることでより関連性の高い記事を検索することができます。
実際1,000以上の記事の全文から検索したい語句を正規表現で探してマッチした記事を取り出すといった方法で記事検索を実装すると一度の検索で1秒以上かかったものが、ElasticSearchを用いて最初のTF-IDFによる特徴語抽出で検索を実装すると50ms~100msで検索結果が返ってきました。
元々の条件が悪かったのもありますが、実に10倍以上の速度で検索が可能でさらに記事が増えても速度差は広がっていくでしょう。
こういった手法に支えられ現在使用している検索という機能が実現しています。














記事を検索
-
お問い合わせ
SiTest の導入検討や
他社ツールとの違い・比較について
弊社のプロフェッショナルが
喜んでサポートいたします。 -
コンサルティング
ヒートマップの活用、ABテストの実施や
フォームの改善でお困りの方は、
弊社のプロフェッショナルが
コンサルティングいたします。
今すぐお気軽にご相談ください。
今すぐお気軽に
ご相談ください。
(平日 10:00~19:00)
今すぐお気軽に
ご相談ください。
0120-90-5794
(平日 10:00~19:00)
グラッドキューブは
「ISMS認証」を取得しています。

認証範囲:
インターネットマーケティング支援事業、インターネットASPサービスの提供、コンテンツメディア事業
「ISMS認証」とは、財団法人・日本情報処理開発協会が定めた企業の情報情報セキュリティマネジメントシステムの評価制度です。